Internal Working of Java HashMap
1. Map and HashMap
Map is a collection which stores elements as key-value pairs. A map cannot contain duplicate keys and each key can map to at most one value. The interface includes methods for basic operations (such as , , , , , , and ), bulk operations (such as and ), and collection views (such as , , and ).
HashMap implements interface in java. It is not synchronized and is not thread safe. Here is an example how to use in java:
Output:
HashMap works with Hashing. To understand Hashing , we should understand first about , and .
1.1. What is Hashing
Lets consider an array that is not sorted and the problem is searching a value in the array. The search requires comparing all elements of the array. So, the time complexity is O(n) . If the array is sorted, a binary search can reduce the time complexity to O(log n). Also, the search can be faster if there is a function which returns an index for each element in the array. In that case the time complexity is reduced to a constant time O(1). Such a function is called Hash Function. A hash function is a function which for a given key, generates a Hash Value.
Java has a hash function which called . The method is implemented in the Object class and therefore each class in Java inherits it. The hash code provides the hash value. Here is the implementation of hashCode method in Object class.
1.2. What is bucket?
A bucket is used to store key-value pairs. A bucket can have multiple key-value pairs. In hashMap, bucket uses simple linkedlist to store objects.
2. HashMap implementation inside Java
In HashMap, calls on the key object and uses the returned hashValue to find a bucket location where keys and values are stored as an Entry object. Here is the implementation of in java.
also checks whether the key is null or not. There can be only one null key in HashMap. If the key is null, then the null key always map to hash 0, then index 0. If the key is not null, then it will call hash function on the key object (See the line 8 in the code above).
Now, the hashValue is used to find the bucket location at which Entry object is stored. Entry object stores in the bucket as (hash, key, value, bucket index). Then, the value object is returned.
Tip
The time complexity of HashMap and method is O(1) as it uses hashCode to find the value.
The time complexity of HashMap and method is O(1) as it uses hashCode to find the value.
What about if two keys have the same hashcode? Here, the implementation of method for key object is become important.
The bucket is a linkedlist but not . HashMap has its own implementation of the linkedlist. Therefore, it traverses through linkedlist and compares keys in each entry using until returns true. Then, the value object is returned. In the following image, you can see that two keys have the same hashcode.
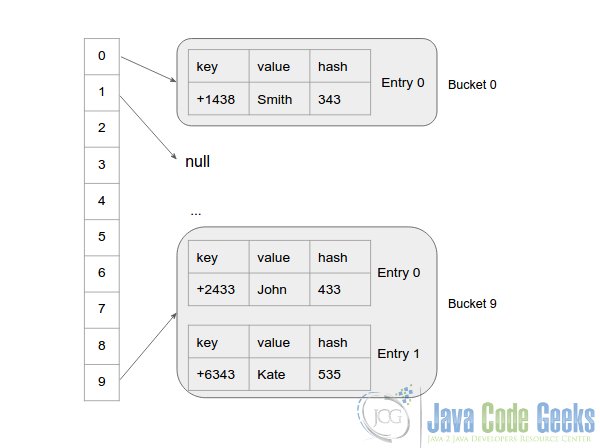
Also, if when two keys are same and have the same hashcode, then the previous key-value pair is replaced with the current key-value pair.
It is important that in Map, any class can serve as a key if and only if it overrides the and method. Also, it is the best practice to make the key class an immutable class.
2.1 HashMap performance
An instance of HashMap has two attributes that affect its performance: initial capacity and load factor.
The capacity is the number of buckets in the hashMap. The initial capacity is the capacity when the hashMap is created.
The load factor is a measure of how full the HashMap is allowed to get, before its capacity is automatically increased. When the number of entries in the HashMap exceeds the product of the load factor and the current capacity, the hashMap is rehashed. Then, the HashMap has approximately twice the number of buckets. In HashMap class, the default value of load factor is 0.75.
3. Conclusion
Now that you know how HashMap works internally in Java, you might want to know about the implementation of HashSet inside Java and how it works. Because these sort of questions shows that candidate has a good knowledge of Collection.
Comments
Post a Comment